VibeCoding
As a CTO, I don’t typically get a lot of time to sit and code—there’s a lot of grunt work involved in my role. Quite a bit of my time goes into the operational aspects of running an engineering team: feature prioritization, production issue reviews, cloud cost reviews, one-on-ones, status updates, budgeting, etc.
Although I’m deeply involved in architecture, design, and scaling decisions, I’m not contributing as a senior developer writing code for features in the product as much as I’d like. It’s not just about writing code—it’s about maintaining it. And with everything else I do, I felt I didn’t have the time or energy to maintain a complex feature.
Over the past couple of years—apart from AI research work—my coding has been pretty much limited to pair programming or contributing to some minor, non-critical features. Sometimes I end up writing small utilities here and there.
Pair Programming as a Connection Tool
I love to pair program with at least two engineers for a couple of hours every week. This gives me an opportunity to connect with them 1:1, understand the problems on the ground, and help them see the bigger picture of how the features they’re working on fit into our product ecosystem.
1:1s were never effective for me. In that 30-minute window, engineers rarely open up. But if you sit and code for 2–3 hours at a stretch, you get to learn a lot about them—their problem-solving approach, what motivates them, and more.
I also send out a weekly video update to the engineering team, where I talk about the engineers I pair programmed with, their background, and what we worked on. It helps the broader engineering team learn more about their peers as well.
The Engineer in Me
The engineer in me always wants to get back to coding—because there’s no joy quite like building something and making it work. I’m happiest when I code.
I’ve worked in several languages over the years—Java, VB6, C#, Perl, good old shell scripting, Python, JavaScript, and more. Once I found Python, I never looked back. I absolutely love the Python community.
I’ve been a full-stack developer throughout my career. My path to becoming a CTO was non-traditional (that’s a story for another blog). I started in a consulting firm and worked across different projects and tech stacks early on, which helped me become a well-rounded full-stack engineer.
I still remember building a simple timesheet entry application in 2006 using HTML and JavaScript (with AJAX) for a client’s invoicing needs. It was a small utility, but it made timesheet entry so much easier for engineers. That experience stuck with me.
I’ll get to why being a full-stack engineer helped me build the app using VibeCoding shortly.
The Spark: Coffee with Shuveb Hussain
I was catching up over coffee with Shuveb Hussain, founder and CEO of ZipStack. Their product, Unstract, is really good for extracting entities from different types of documents. They’ve even open-sourced a version—go check it out.
Shuveb, being a seasoned engineer’s engineer, mentioned how GenAI code editors helped him quickly build a few apps for his own use over a weekend. That sparked something in me: why wasn’t I automating my grunt work with one of these GenAI code editors?
I’ve used GitHub Copilot for a while, but these newer GenAI editors—like Cursor and Windsurf—are in a different league. Based on Shuveb’s recommendation, I chose Windsurf.
Let’s be honest though—I don’t remember any weekend project of mine that ended in just one weekend 😅
The Grunt Work I Wanted to Automate
I was looking for ways to automate the boring but necessary stuff, so I could focus more on external-facing activities.
Every Thursday, I spent about 6 hours analyzing production issues before the weekly Friday review with engineering leaders, the SRE team, product leads, and support. I’d get a CSV dump of all the tickets and manually go through each one to identify patterns or repeated issues. Then I’d start asking questions on Slack or during the review meeting.
The process was painful and time-consuming. I did this for over 6 months and knew I needed to change something.
In addition to that:
- I regularly reviewed cloud compute costs across environments and products to identify areas for optimization.
- I monitored feature usage metrics to see what customers actually used.
- I examined job runtime stats (it’s a low-code platform, so this matters).
- I looked at engineering team metrics from the operations side.
Each of these lived in different tools, dashboards, or portals. I was tired of logging into 10 places and context-switching constantly while fielding distractions.
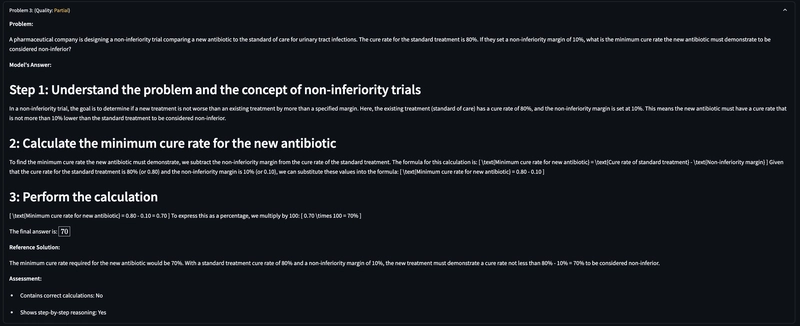
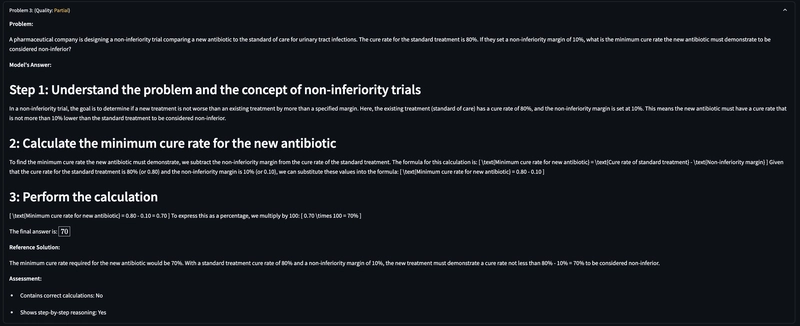
The Build Begins: CTO Dashboard
I decided to build an internal tool I nicknamed CTODashboard—to consolidate everything I needed.
My Tech Stack (via Windsurf):
- Frontend: ReactJS
- Backend: Python (FastAPI)
- Database: Postgres
- Deployment: EC2 (with some help from the SRE team)
I used Windsurf’s Cascade interface to prompt out code, even while attending meetings. It was surprisingly effective… except for one time when a prompt completely messed up my day’s work. Lesson learned: commit code at every working logical step.
In a couple of days, I had:
- A feature to upload the CSV dump
- Filters to slice and dice data
- A paginated data table
- Trend analytics with visualizations
Even when I hit errors, I just screenshot them or pasted logs into Windsurf and asked it to fix them. It did a decent job. When it hallucinated or got stuck, I just restarted with a fresh Cascade.
I had to rewrite the CSV upload logic manually when the semantic mapping to the backend tables went wrong. But overall, 80% of the code was generated—20% I wrote myself. And I reviewed everything to ensure it worked as intended.
Early Feedback & Iteration
I gave access to a couple of colleagues for early feedback. It was overwhelmingly positive. They even suggested new features like:
- Summarizing long tickets
- Copy-pasting ticket details directly into Slack
- Copying visualizations without taking screenshots
I implemented all of those using Windsurf in just a few more days.
In under a week, I had an MVP that cut my Thursday analysis time from 6+ hours to under 2.

Then Abhay Dandekar, another senior developer, offered to help. He built a Lambda function to call our Helpdesk API every hour to fetch the latest tickets and updates. He got it working in 4 hours—like a boss.
Growing Usage
Word about the dashboard started leaking (okay, I may have leaked it myself 😉). As more people requested access, I had to:
- Add Google Sign-In
- Implement authorization controls
- Build a user admin module
- Secure the backend APIs with proper access control
- Add audit logs to track who was using what
I got all this done over a weekend. It consumed my entire weekend, but it was worth it.
AWS Cost Analytics Module
Next, I added a module to analyze AWS cost trends across production and non-prod environments by product.
Initially, it was another CSV upload feature. Later, Abhay added a Lambda to fetch the data daily. I wanted engineering directors to see the cost implications of design decisions—especially when non-prod environments were always-on.
Before this, I spent 30 minutes daily reviewing AWS cost trends. Once the dashboard launched, engineers started checking it themselves. That awareness led to much smarter decisions and significant cost savings.
I added visualizations for:
- Daily cost trends
- Monthly breakdowns
- Environment-specific views
- Product-level costs
More Modules Coming Soon
I’ve since added:
- Usage metrics
- Capitalization tracking
- (In progress): Performance and engineering metrics
The dashboard now has 200+ users, and I’m releasing access in batches to manage performance.
Lessons Learned from VibeCoding
This was a fun experiment to see how far I could go with GenAI-based development using just prompts.
What I Learned:
- Strong system design fundamentals are essential.
- Windsurf can get stuck in loops—step in and take control.
- Commit frequently. Mandatory.
- You’re also the tester—don’t skip this.
- If the app breaks badly, roll back. Don’t fix bad code.
- GenAI editors are great for senior engineers; less convinced about junior devs.
- Model training cutoffs matter—it affects library choices.
- Write smart prompts with guardrails (e.g., “no files >300 lines”).
- GenAI tools struggle to edit large files (my
app.py hit 5,000 lines; I had to refactor manually).
- Use virtual environments—GenAI often forgets.
- Deployments are tedious—I took help from the SRE team for Jenkins/Terraform setup.
- If you love coding, VibeCoding is addictive.
Gratitude
Special thanks to:
- Bhavani Shankar, Navin Kumaran, Geetha Eswaran, and Sabyasachi Rout for helping with deployment scripts and automation (yes, I bugged them a lot).
- Pravin Kumar, Vikas Kishore, Nandini PS, and Prithviraj Subburamanian for feedback and acting as de facto product managers for dashboard features.